In earlier days, webpages written around a particular topic were fewer as compared to today where large sets of data compete against each other in order to satisfy the demands of the users. Google is having a hard time in deciding which content is of higher quality than the other. Businesses are producing content on a large scale and inserting keywords in them in order to get them ranked on Google. The goal is to get more traffic and leads. But, in this rat and mouse game, who will think of the user? Google knows this really well that if the result quality declines, users will leave Google and this fear is making Google engineers think hard as to how they can filter out “filler web pages” that do not serve the real purpose of educating the users but rather are used as a tactic to bring more visitors on the site.
The Panda update launched in Feb 23, 2011 was a great beginning to end the dominance of inferior quality content. Since then, 27 updates of Panda have happened, each update bringing in new signals for detecting low quality content and penalizing them in the search results. Recent update was the Panda 4.1 that specifically targeted on keyword stuffing, low quality affiliate sites that embedded contextual affiliate links many times within the content body, less secure sites and sites engaging in any form of cloaking. If we think from Google’s point of view then it is really hard but necessary for Google to constantly wipe out these low quality resources from the search results.
Now, let’s move on the interesting part as to how Google might predict the site quality based on site quality scores and by generating a phrase model.
Phrase Model – Google’s Way of Detecting Low Quality Sites
Internet search engines like Google constantly index,identify, process and rank resources like, e.g., web pages, images, text documents, multimedia content, that are relevant to a user’s information needs and to present information about the resources in a manner that is most useful to the user. They return a set of search results consisting of respective resources that satisfies the users information needs.
A better way to determine the quality of a resource is by assigning it a score that represents a measure of quality for the site. The site quality score for a site can be used as ranking signal to identify and rank resources. Here are the steps that might happen in actual processing of search query:
1- User enters a search query.
2- Query is received by the search engine through the search system.
3- Search engine identifies resources that satisfy the query with the help of the index database.
4- Search engine processes the query using ranking engine or other software that generates scores for the resources that satisfy the query and ranks the resources according to their respective scores.
5- The end result is displayed before the user.
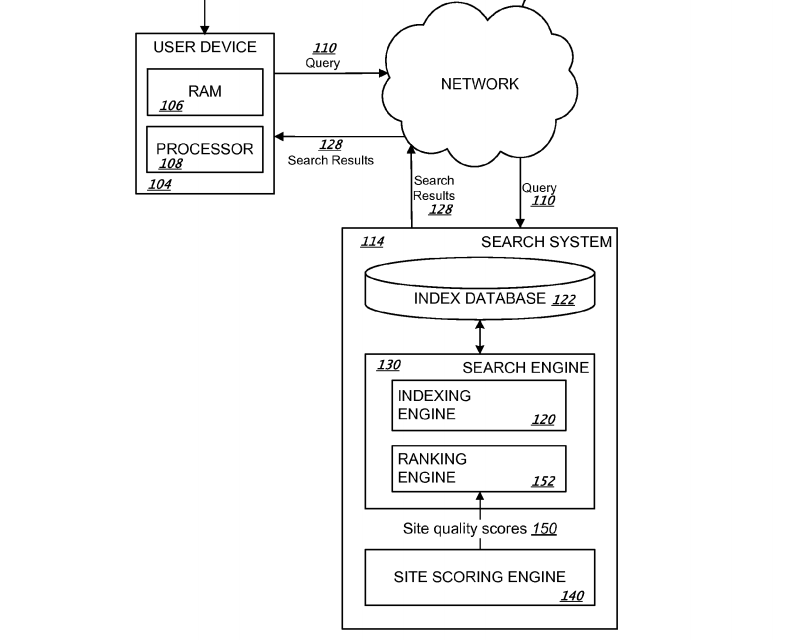 |
| Figure displays how a search query might get processed by Google search engine. |
A search engine comprises of 3 main parts:
INDEXING ENGINE – Helps to index resources on the Internet.
INDEX DATABASE – Helps to store the index information.
RANKING ENGINE – Generates scores and ranks resources based on those scores.
Additionally, the search engine can also communicate with a SCORING ENGINE that uses phrase models to generate site quality scores for sites.
For each site in a collection of sites, determine which n-grams, of a set of n-grams, occur on the site. For each site in a collection of sites (can be a collection of previously scored sites), determine which n-grams, of a set of n-grams, occur on the site .The n-grams are n-grams of tokens, including punctuation tokens. In an ideal scenario, n-gram is a 3-gram but it can be a 2-gram, 4-grams or 5-grams. In some implementations, n-grams of different lengths are used. In other implementations, n-
grams of only one length are used.
N-grams can be infrequent or regular. Infrequent n-grams are n-grams that occur on very few sites, e.g., fewer than 10, 50, 75 or 100 sites. In computation of n-grams, relevancy of content is computed, pages are considered to include content from sources like anchor text of links pointing to the pages although the same content is not present on the pages. For each site, relative frequency measure for each n-gram is calculated, which is based on the count of pages divided by the number of pages
on the site. Now, a map is generated from n-grams to sites.
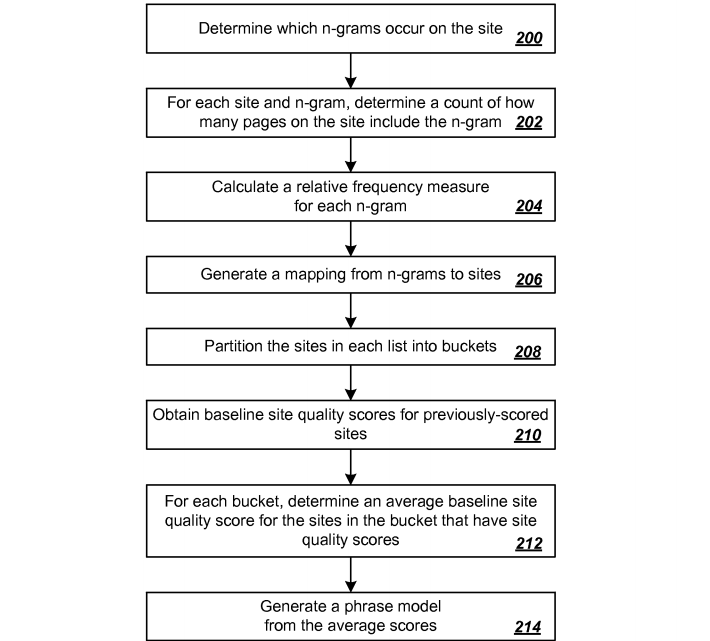 |
| Computation of site quality score base on phrase model |
Now, the site partitioned into buckets in the range of 20 to 100, e.g., 20, 40, 60, 70, 80, 90 or 100. An average baseline site quality score is determined. Thereafter a phrase model from the average scores for each phrase. The global average may be seen as, and referred to as, a “neutral” site quality score. The two averages can be considered “very close” if phrase averages are all within 0.2%, 0.5%, 1%, 2%, 2.5%, 3% or 5%, for example, of the neutral score. An example of a 2-gram phrase that can be excluded is “on the”, which empirically is almost equally likely to appear in a high quality site as in a low quality site.
The presence of “on the” on a site therefore provides little information on site quality.
This model is very much similar to the TF-IDF score which measures the term frequency and the inverse document frequency.
What Does This Means For Website Content?
If you have read about the technical aspects of the algorithm as described above, you must have got a hint how to proceed further with your content marketing. Else, if you found the technical aspects too hard to understand, here I present you a simple explanation for it:
“Google might generate n-grams which are a contiguous sequence of n items from a given sequence of text or speech. Such tokens for selected phrase are used in the content a score is generated for each one of them. Individual or average scores might be generated. Based on these scores, sites may be grouped into several lists. The anchor text pointing to a webpage is seen as a phrase that actually appears on the page. Based on the average scores of phrases, a phrase model is generated which ultimately the main score for each site. The higher the score, the better the chances of ranking.”
Key Takeaways:
1- Create content that uses unique but relevant words in them.
2- Do not repeat keywords again and again in the content.
3- Use phrase based anchor text when linking to your site. Do not overdo it else it might be harmful.
4- Select phrases from sites that are already ranking higher within your niche and use them in your content. This will allow your site to fall in the same topic category (remember, the list of selected sites?). Do not copy or spam, get ideas and use them in a user friendly manner.
5- Every word used in the main areas of the webpage like the H1 tag might hold significant value so make sure those words add to your aggregate score.
6- Do not produce too many pages on the same topic. This might reduce your overall site score.
The full patent for determining site quality can be read here, one of inventors of this patent is Navneet Panda (the man behind the Panda Update).
Did you found this post useful? Please share your comments below:
Also See:
Read Some of Google’s First Patents Filed by Larry Page and Sergey Brin
Ranking Documents is Set to Penalize Spammers
New Google Patent to Identify Spam in Information Collected From a Source
How Google Uses Contextual Search Terms
Taxonomic Classification to Find Real Context of Words
Google Tag Manager
How Google Identifies Entities Using Attributes
Trust Button and Persona Pages
Anchor Text Variation and Seo
5 Points Every Seo Must Follow
Importance of Backlinks in Seo
Site Wide Links
Are You Making Your Website Vulnerable to Future Google Updates?
Types of Graphs Google Uses to Rank Webpages
Universal Analytics
Seo Guide for Schema Vocabulary
How to Tag a Site in Google Webmasters?
Google Local Carousel